guest post by Marc Harper
In John’s information geometry series, he mentioned some of my work in evolutionary dynamics. Today I’m going to tell you about some exciting extensions!
The replicator equation
First a little refresher. For a population of 
To see why this equation should be true, let 


The Lotka–Volterra equation is a very general rule for how these numbers can change with time:

Each population grows at a rate proportional to itself, where the ‘constant of proportionality’, 
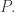

Let 

These numbers
Again, we can bundle these numbers into a vector:

which we call the population distribution. It turns out that the Lotka–Volterra equation implies the replicator equation:

where

is the mean fitness of all the individuals. You can see the proof in Part 9 of the information geometry series.
By the way: if each fitness 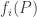

From now on, when talking about this equation, that’s what I’ll do.
Anyway, the take-home message is this: the replicator equation says the fraction of individuals of any type changes at a rate proportional to fitness of that type minus the mean fitness.
Now, it has been known since the late 1970s or early 1980s, thanks to the work of Akin, Bomze, Hofbauer, Shahshahani, and others, that the replicator equation has some very interesting properties. For one thing, it often makes ‘relative entropy’ decrease. For another, it’s often an example of ‘gradient flow’. Let’s look at both of these in turn, and then talk about some new generalizations of these facts.
Relative entropy as a Lyapunov function
I mentioned that we can think of a population distribution as a probability distribution. This lets us take ideas from probability theory and even information theory and apply them to evolutionary dynamics! For example, given two population distributions 



This measures how much information you gain if you have a hypothesis about some state of affairs given by the probability distribution 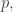
It may seem weird to treat a population distribution as a hypothesis, but this turns out to be a good idea. Evolution can then be seen as a learning process: a process of improving the hypothesis.
We can make this precise by seeing how the relative information changes with the passage of time. Suppose we have two population distributions 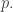

For the proof, see Part 11 of the information geometry series.
So, the information of

If
What matters now is that when 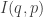

and 

People summarize all this by saying that relative information is a ‘Lyapunov function’. Very roughly, a Lyapunov function is something that decreases with the passage of time, and is zero only at the unique stable state. To be a bit more precise, suppose we have a differential equation like

where 



is a Lyapunov function if
• 
• 

and
• 
In this situation, the point 
The replicator equation as a gradient flow equation
The basic idea of Lyapunov’s theorem is that when a ball likes to roll downhill and the landscape has just one bottom point, that point will be the unique stable equilibrium for the ball.
The idea of gradient flow is similar, but different: sometimes things like to roll downhill as efficiently as possible: they move in the exactly the best direction to make some quantity smaller! Under certain conditions, the replicator equation is an example of this phenomenon.
Let’s fill in some details. For starters, suppose we have some function

Think of 

Here 

where 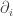
The interesting thing is that under certain conditions, the replicator equation is an example of a gradient flow equation… but typically not one where
The space of all population distributions is a simplex:

For example, it’s an equilateral triangle when 

In fact this trick works in any dimension. The idea is to give the simplex a special Riemannian metric, the ‘Fisher information metric’. The usual metric on Euclidean space is

This simply says that two standard basis vectors like 


As before, 

We saw how this formula arises from information theory back in Part 7. I won’t repeat the calculation, but the idea is this. Fix a population distribution 
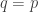

and this point is a local minimum for the relative information. So, the first derivative of

But the second derivatives are not zero. In fact, since we’re at a local minimum, it should not be surprising that we get a positive definite matrix of second derivatives:

And, this is the Fisher information metric! So, the Fisher information metric is a way of taking dot products between vectors in the simplex of population distribution that’s based on the concept of relative information.
This is not the place to explain Riemannian geometry, but any metric gives a way to measure angles and distances, and thus a way to define the gradient of a function. After all, the gradient of a function should point at right angles to the level sets of that function, and its length should equal the slope of that function:

So, if we change our way of measuring angles and distances, we get a new concept of gradient! The

where 

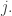

Now suppose the fitness landscape is the good old Euclidean gradient of some function. Then it turns out that the replicator equation is a special case of gradient flow on the space of population distributions… but where we use the Fisher information metric to define our concept of gradient!
To get a feel for this, it’s good to start with the Lotka–Volterra equation, which describes how the total number of individuals of each type changes. Suppose the fitness landscape is the Euclidean gradient of some function

Then the Lotka–Volterra equation becomes this:

This doesn’t look like the gradient flow equation, thanks to that annoying

For a proof, and the formula for this other metric, see Section 3.7 in this survey:
• Marc Harper, Information geometry and evolutionary game theory.
Now let’s turn to the replicator equation:

Again, if the fitness landscape is a Euclidean gradient, we can rewrite the replicator equation as a gradient flow equation… but again, not with respect to the Euclidean metric. This time we need to use the Fisher information metric! I sketch a proof in my paper above.
In fact, both these results were first worked out by Shahshahani:
• Siavash Shahshahani, A New Mathematical Framework for the Study of Linkage and Selection, Memoirs of the AMS 17, 1979.
New directions
All this is just the beginning! The ideas I just explained are unified in information geometry, where distance-like quantities such as the relative entropy and the Fisher information metric are studied. From here it’s a short walk to a very nice version of Fisher’s fundamental theorem of natural selection, which is familiar to researchers both in evolutionary dynamics and in information geometry.
You can see some very nice versions of this story for maximum likelihood estimators and linear programming here:
• Akio Fujiwara and Shun-ichi Amari, Gradient systems in view of information geometry, Physica D: Nonlinear Phenomena 80 (1995), 317–327.
Indeed, this seems to be the first paper discussing the similarities between evolutionary game theory and information geometry.
Dash Fryer (at Pomona College) and I have generalized this story in several interesting ways.
First, there are two famous ways to generalize the usual formula for entropy: Tsallis entropy and Rényi entropy, both of which involve a parameter 
• conditions under which relative entropy is a Lyapunov function for the replicator equation, and
• conditions under which the replicator equation is a special case of gradient flow
generalize to these cases! However, these generalized entropies give modified versions of the replicator equation. When we set 
• Marc Harper, Escort evolutionary game theory.
My initial interest in these alternate entropies was mostly mathematical—what is so special about the corresponding geometries?—but now researchers are starting to find populations that evolve according to these kinds of modified population dynamics! For example:
• A. Hernando et al, The workings of the Maximum Entropy Principle in collective human behavior.
There’s an interesting special case worth some attention. Lots of people fret about the relative entropy not being a distance function obeying the axioms that mathematicians like: for example, it doesn’t obey the triangle inequality. Many describe the relative entropy as a distance-like function, and this is often a valid interpretation contextually. On the other hand, the 

This equation is called the projection dynamic.
Later, I showed that there is a reasonable definition of relative entropy for a much larger family of geometries that satisfies a similar distance minimization property.
In a different direction, Dash showed that you can change the way that selection acts by using a variety of alternative ‘incentives’, extending the story to some other well-known equations describing evolutionary dynamics. By replacing the terms 

where 
Dash showed that there is a natural generalization of evolutionarily stable states to ‘incentive stable states’, and that for incentive stable states, the relative entropy is decreasing to zero when the trajectories get near the equilibrium. For the logit and projection dynamics, incentive stable states are simply evolutionarily stable states, and this happens frequently, but not always.
The third generalization is to look at different ‘time-scales’—that is, different ways of describing time! We can make up the symbol 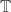

But we can also treat time as coming in discrete evenly spaced steps, which amounts to treating time as an integer:

More generally, we can make the steps have duration 


There is a nice way to simultaneously describe the cases 



and using this as a substitute for the derivative gives difference equations like a discrete-time version of the replicator equation. There are many other choices of time-scale, such as the quantum time-scale given by 

Remarkably, Dash and I were able to show that you can combine all three of these generalizations into one theorem, and even allow for multiple interacting populations! This produces some really neat population trajectories, such as the following two populations with three types, with fitness functions corresponding to the rock-paper-scissors game. On top we have the replicator equation, which goes along with the Fisher information metric; on the bottom we have the logit dynamic, which goes along with the Euclidean metric on the simplex:


From our theorem, it follows that the relative entropy (ordinary relative entropy on top, the 
The final form of the theorem is loosely as follows. Pick a Riemannian geometry given by a metric 


When there isn’t such a stable state, we still get some interesting population dynamics, like the following:


See this paper for details:
• Marc Harper and Dashiell E. A. Fryer, Stability of evolutionary dynamics on time scales.
Next time we’ll see how to make the main idea work in finite populations, without derivatives or deterministic trajectories!